Table of Contents
Data Models: A Comprehensive Guide to Structuring Information for Optimal Insights and Decision-Making
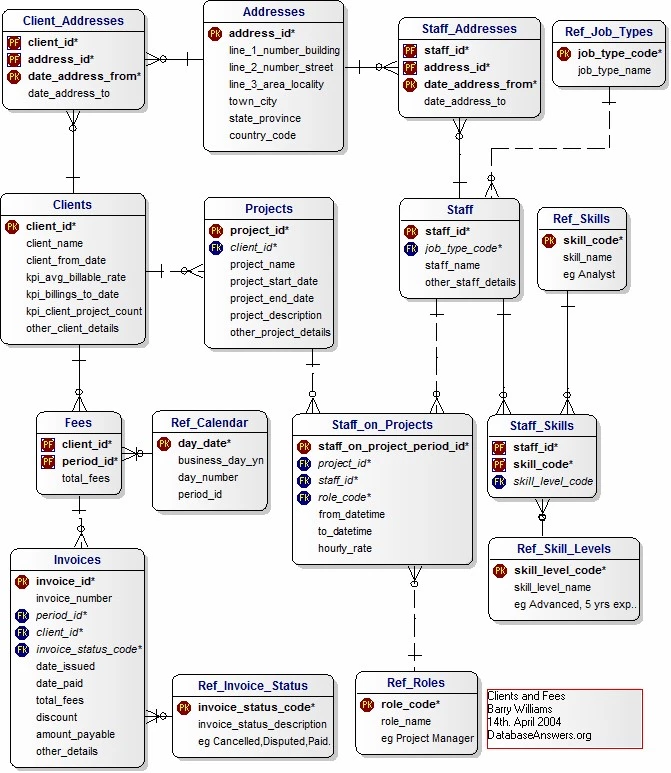
In the realm of data management, the use of effective data models plays a pivotal role in organizing and representing information in a structured and meaningful way. Data models serve as the blueprint for databases, facilitating efficient data storage, retrieval, and analysis. This article delves into the world of data models, exploring their importance, various types, and best practices for designing and implementing them.
Understanding Data Models:
- Definition and Purpose:
Data models are conceptual frameworks that define the structure, relationships, and constraints of data in a database system. They provide a visual representation of how data elements are organized and interact with each other. The primary purpose of a data model is to ensure data integrity, facilitate efficient data management, and support effective decision-making. - Importance of Data Models:
a. Data Organization: Data models help organize information by identifying entities (objects), attributes (properties), and relationships between entities. They provide a clear and structured view of the data, enabling users to understand and work with it more effectively.
b. Data Consistency: By defining relationships and constraints, data models ensure consistency and accuracy in data storage. They help maintain data integrity, preventing the insertion of erroneous or inconsistent information into the database.
c. Data Integration: Data models serve as a common language between different stakeholders, facilitating data integration across various systems and departments. They promote interoperability and data exchange between applications, enabling seamless data flow.
d. Decision-Making: A well-designed data model supports data analysis and reporting, providing valuable insights for decision-making. It enables users to query and retrieve data efficiently, helping organizations gain actionable intelligence.
Types of Data Models:
- Hierarchical Data Model:
The hierarchical model represents data in a tree-like structure, with parent-child relationships. It is characterized by a top-down approach, where each entity has a single parent, and child entities are organized in a hierarchical manner. This model was popular in early database systems but has limited flexibility. - Network Data Model:
The network model extends the hierarchical model by allowing entities to have multiple parents, creating complex relationships. It introduced the concept of sets and pointers, enhancing data retrieval capabilities. While more flexible than the hierarchical model, it is still complex and challenging to manage. - Relational Data Model:
The relational model is the most widely used data model today. It organizes data into tables, where each table represents an entity, and the relationships between entities are defined through primary and foreign keys. This model offers simplicity, flexibility, and powerful querying capabilities, making it the foundation for modern relational database systems. - Entity-Relationship (ER) Model:
The ER model focuses on defining entities, attributes, and relationships between entities. It uses entities as building blocks and illustrates their relationships through diagrams. The ER model serves as a precursor to the relational model and helps in visualizing database structures. - Object-Oriented Data Model:
The object-oriented model represents data as objects that encapsulate both data and behaviors. It supports inheritance, encapsulation, and polymorphism, allowing for more complex data structures. This model is particularly useful for applications with complex data requirements, such as multimedia systems or object-oriented programming languages. - NoSQL Data Models:
NoSQL (Not Only SQL) data models are designed to handle large volumes of unstructured or semi-structured data. They include key-value stores, document databases, columnar databases, and graph databases. These models provide scalability, high performance, and flexibility for specific use cases.
Designing and Implementing Data Models:
- Conceptual Data Modeling:
Conceptual data modeling involves understanding the requirements, identifying entities and their attributes, and establishing relationships between entities. It focuses on the high-level view of the data, without considering implementation details. Techniques such as Entity-Relationship (ER) modeling are commonly used for conceptual data modeling. - Logical Data Modeling:
Logical data modeling translates the conceptual model into a representation that aligns with the chosen database management system (DBMS). It involves defining tables, columns, primary and foreign keys, and normalization techniques to eliminate redundancy and ensure data integrity. The resulting model is independent of any specific DBMS. - Physical Data Modeling:
Physical data modeling focuses on translating the logical data model into a specific DBMS implementation. It includes considerations such as storage structures, indexing strategies, partitioning, and performance optimizations. The physical data model ensures efficient data storage and retrieval, taking into account the specific characteristics and capabilities of the chosen DBMS. - Best Practices for Data Modeling:
a. Understand the Business Requirements: Thoroughly analyze the business requirements and engage stakeholders to ensure the data model aligns with the organization’s goals and objectives.
b. Keep it Simple: Strive for simplicity and clarity in the data model design. Avoid unnecessary complexity that may hinder understanding and maintenance.
c. Normalize Data: Apply normalization techniques to eliminate data redundancy, reduce update anomalies, and improve data integrity.
d. Establish Naming Conventions: Define consistent naming conventions for entities, attributes, and relationships to ensure clarity and ease of understanding.
e. Document the Data Model: Document the data model comprehensively, including its purpose, entities, attributes, relationships, and any business rules or constraints. This documentation serves as a valuable reference for future development, maintenance, and training.
f. Iterate and Refine: Data modeling is an iterative process. Continuously review and refine the data model as the understanding of business requirements evolves and new insights emerge.
Implementing Data Models in Practice:
- Database Creation:
Use a DBMS to create the physical database based on the finalized data model. Define tables, columns, and relationships according to the logical and physical data models. - Data Migration:
If migrating from an existing system, plan and execute data migration strategies to ensure a smooth transition from the old database to the new data model. This involves extracting, transforming, and loading data into the new database structure. - Testing and Validation:
Thoroughly test the data model and the associated database for accuracy, data integrity, and performance. Validate the model against business requirements and ensure it meets the expected functionality. - Maintenance and Evolution:
Data models should be treated as living artifacts that require ongoing maintenance and evolution. As business requirements change or new features are introduced, update and modify the data model accordingly.
Finally:
Data models are fundamental to effective data management and decision-making. They provide structure, organization, and relationships to data, ensuring data integrity, consistency, and optimal retrieval. By understanding the various types of data models and following best practices for designing and implementing them, organizations can unlock the full potential of their data, improve operational efficiency, and gain valuable insights for informed decision-making.